



































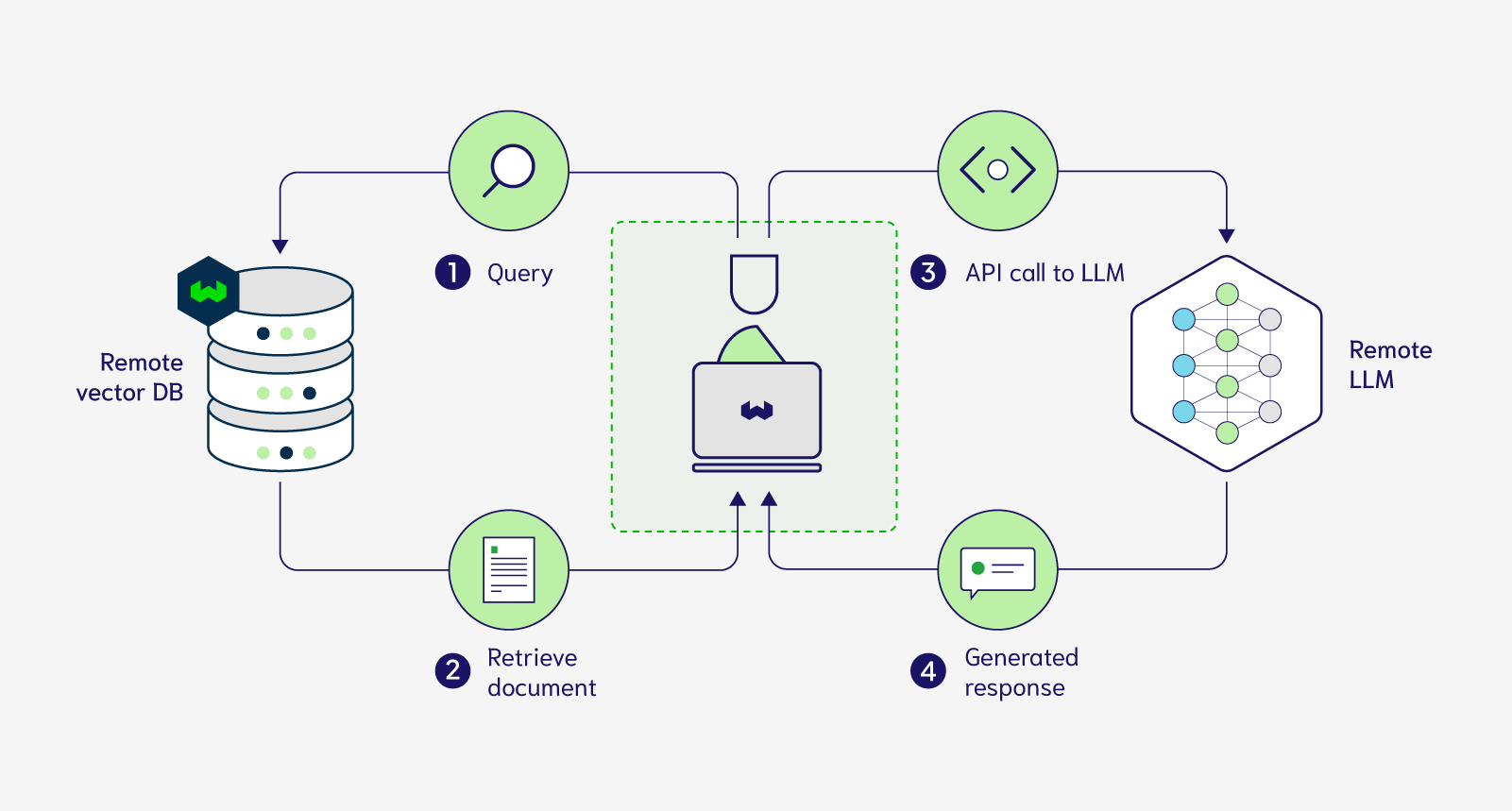
In the world of artificial intelligence, the pursuit of more efficient and accurate models is an ongoing journey. One of the significant advancements in this field is the emergence of the Block-Attention mechanism for Retrieval Augmented Generation (RAG), which is bringing about a new era of low-latency and enhanced performance.
The Significance of RAG in the Industrial Realm
- The Power of RAG: In industrial scenarios, retrieval technology is often employed to add knowledge documents from external databases to large language models, enhancing the credibility of their responses. RAG is widely recognized as one of the most effective ways to infuse domain-specific knowledge into LLM.
- Challenges Faced by RAG: However, RAG is not without its drawbacks. In practical applications, to ensure the recall of documents containing correct knowledge, multiple documents (usually between 5 and 30) are retrieved for each user query and integrated into the input prompt for the large language model to process. This leads to a significant increase in the sequence length of the input prompt, resulting in a substantial reduction in inference efficiency. Specifically, measured by the Time To First Token (TTFT), the inference latency of RAG large language models is much higher than that of non-RAG large language models.
The Innovation of Block-Attention
- The Concept of Block-Attention: The recent paper “Block-Attention for Efficient RAG” presents a revolutionary block-attention mechanism for the RAG scenario. By independently encoding the retrieved documents in blocks, the model no longer needs to repeatedly encode and calculate the documents that have already been seen in other queries.
- Implementation of Block-Attention: The implementation of Block-Attention is relatively straightforward. Firstly, all blocks except the last one are independently encoded. Secondly, the position encoding for each block is recalculated. Finally, all the blocks are concatenated together, and the KV State of the last block is calculated. But simply switching the model from self-attention to block-attention without any modifications would confuse the large language model, as it has never seen the input encoded in the block-attention way during the training stage.
Experimental Results and Analyses
- Accuracy Comparison: In the experiments, the authors aimed to explore two key questions. Firstly, whether the block-attention model can achieve the same accuracy as the self-attention model in the RAG scenario. The results showed that a direct switch from self-attention to block-attention is not advisable as it leads to a sharp drop in accuracy. However, with fine-tuning using the block-attention mechanism, the resulting model performs almost the same as the self-attention model, and even slightly better in some datasets. Additionally, the position re-encoding operation is crucial for the block-attention model, and removing it leads to a significant performance decline.
- Efficiency Enhancement: The authors also verified the improvement in efficiency through another set of experiments. By fixing the length of the user’s question at 50 tokens and gradually increasing the number of retrieved documents, the total length of the input sequence was increased from 50 to 32K. The Time To First Token (TTFT) and Floating-point Operations To First Token (FLOPs-TFT) of the model under different prompt lengths demonstrated remarkable results. As the text length increases, the importance of block-attention becomes more prominent.
The Broader Implications and Future Prospects
- Beyond RAG: The authors pointed out that block-attention has important applications in many scenarios beyond RAG. Although due to confidentiality reasons, they cannot disclose how it is used in other industrial applications for the time being, they look forward to the community’s researchers exploring its potential further and applying it in appropriate scenarios.












{kind=link}
Discussion about this post